Abstract
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
Framework
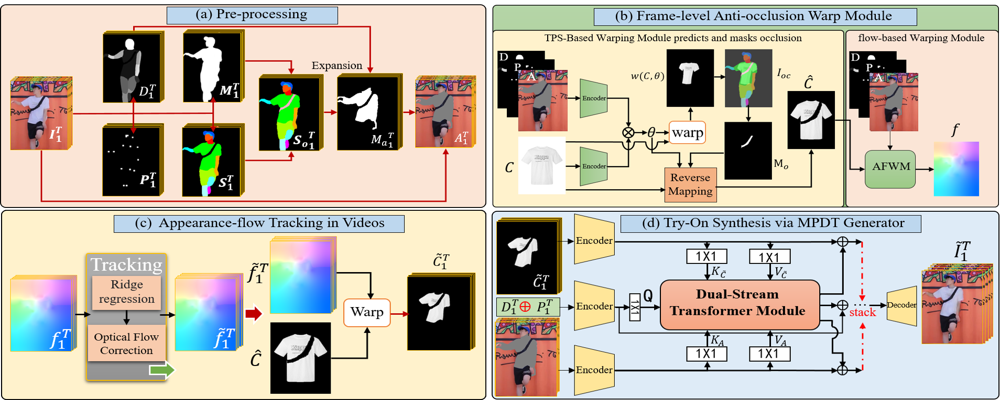
(a) First, we obtain clothing-agnostic person image sequences $A_{1}^{T}$. (b) We predict $t$ warped clothes $ W(C, \theta_{t}) $ by TPS-based warp method to infer an anti-occlusion target clothes $C$, then appearance-flow-based warp method is adopted to get an appearance flow $f$. (c) Appearance-flow tracking module based on ridge regression and optical flow correction is designed to get warped clothing sequence with spatio-temporally consistent. (d) Finally, MPDT generator synthesizes the final output video sequence $\tilde{I}_{1}^{T} $ based on the outputs from the previous stages
Results
VVT
Citation
@inproceedings{jiang2022clothformer,
title={ClothFormer: Taming Video Virtual Try-on in All Module},
author={Jianbin Jiang and Tan Wang and He Yan and Junhui Liu},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}